Ubuntu下编译安装Python
在Ubuntu上编译安装Python并不困难,最重要的一定要提前装好所有的依赖包,否则在用的时候就会遇到诸如ssl问题,找不到_bz2,lzma库等问题。
Spark与TDengine连接总结
TDengine是一款高性能的时序数据库,最近在研究如何在Spark中读取和写入数据,这里记录一下最近的成果。
版本信息:
- Spark版本:2.4.0,yarn集群模式
- Python版本:3.7.9
- Scala版本:2.11.12
- TDengine版本:2.6,商业版
- TAOS-JDBC版本:2.0.42
1. 官方JDBC使用
TDengine官方提供了JDBC,Spark读取和写入均可以直接使用
1.1 依赖问题
- 需要引用taos-jdbcdriver,版本上强烈推荐2.0.42,其他版本会有各种问题(针对2.x系列,3.x系列的没用过);
1 | <dependency> |
Python时间格式总结
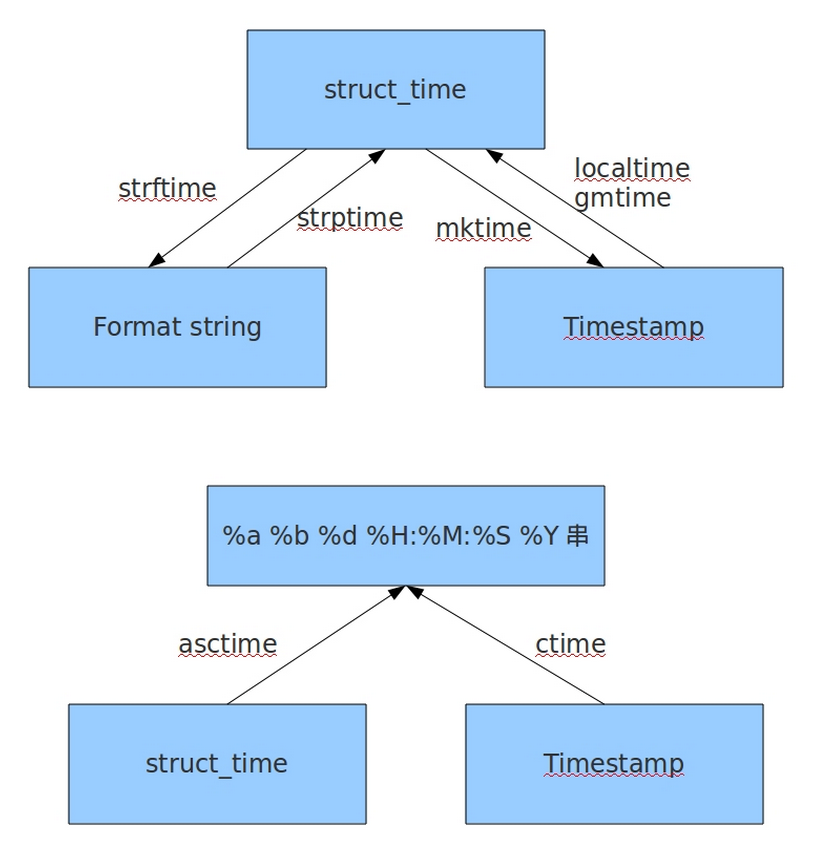
time模块
time模块下时间主要有三种表现形式:
时间戳(timestamp),注意这里所说的时间戳本质上是个数字(int/float),与Pandas中pandas._libs.tslibs.timestamps.Timestamp的timestamp是不一样的;


时间元组(struct_time);
格式化时间,格式化时间还包括自定义格式和固定格式;
以上表现形式生成和相互转换的方式:
时间戳(ts) 时间元组(st) 自定义格式(ft) 固定格式 时间戳 time.time() time.localtime(ts)
time.gmtime(ts)NA time.ctime(ts) 时间元组 time.mktime(st) time.localtime()
time.gmtime()time.strptime(fmt, st) time.asctime(st) 自定义格式 NA NA time.strftime(fmt) NA 固定格式 NA NA NA NA
pandas.dataframe切片总结
df[‘column_name’] ,df[row_start_index, row_end_index]
- 可以通过df[[‘column_name1’, ‘column_name2’]]的方式来指定想选择的单个或多个列;
- 可以通过df[df.index == ‘index’]来选择指定的单个行;
- 可以通过行的序号来指定想选择的单个或多个行;
- 不能通过df[‘index’]的方式来选择指定的行;
- 不能通过列的序号来指定想选择的列;